- YouTube ingestion that extracts transcripts from playlists and individual videos
- Smart Q&A that routes questions to the right source type automatically
- Video recommendations that surface relevant videos instead of synthesized answers
Prerequisites
Before starting, ensure you have:- An Agentset account with a namespace and API key (API Reference)
- An OpenAI API key for response generation
- The Agentset SDK installed (
npm install agentsetorpip install agentset)
YouTube content we’ll ingest
We’ll ingest two types of YouTube content: a conference playlist (12 videos) and individual podcast episodes. Each will be tagged with metadata for smart routing later.- Conference Talks
- Podcasts
Search & Retrieval track from AI Engineer World’s Fair 2025 — 12 talks covering RAG, vector search, agent memory, and production AI systems
Step 1: Ingest a YouTube playlist
Pass a playlist URL and the ingestion automatically extracts each video’s transcript, chunks it, and creates embeddings. We’ll tag this content asconference for routing later.
We will ingest this YouTube playlist
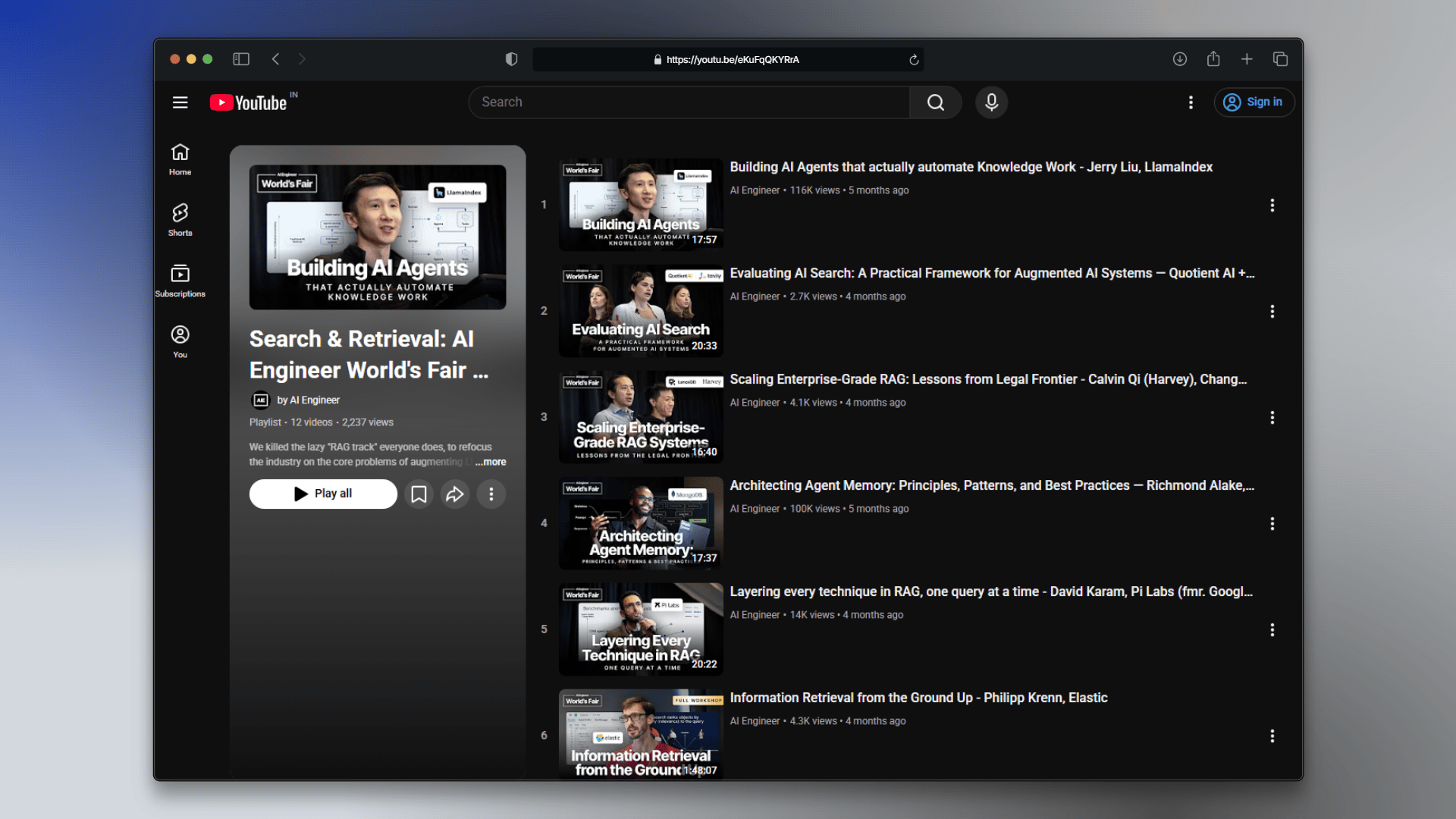
Each video in the playlist becomes a separate document with its own metadata (title, URL, duration). Transcripts are extracted and chunked automatically.
Step 2: Ingest individual YouTube videos
You can also ingest individual video URLs. Here we’ll add some podcast episodes and tag them aspodcast to distinguish them from the conference playlist.
We will ingest these YouTube videos
- Video 1
- Video 2
Wait for both ingestion jobs to complete before searching. Check status via the API or on the dashboard.
Step 3: Basic search
Run a quick search to verify everything is ingested.Step 4: Smart source routing
Not all questions need both sources. Technical “how do I implement X” questions benefit from conference talks. Questions about real-world experiences and opinions benefit from podcasts. Let’s build a router that classifies questions and searches the right source.Classify the question type
Use an LLM to classify each question into one of three categories:Route to the right source
Based on the classification, search the appropriate source:Example: Technical question
A question about implementation routes to conference talks:Example: Opinion question
A question about experiences routes to podcasts:Example: Question needing both perspectives
A broad question searches both sources:Step 5: Generate answers with smart routing
Combine the router with LLM generation to answer questions from the right sources.Step 6: Video recommendations
Sometimes you don’t want an AI-generated answer. You want to know which video to watch. Let’s build a recommender that returns video suggestions instead of synthesized text.Filter recommendations by source type
You can also filter recommendations to only show conference talks or podcasts:Recap
You’ve turned YouTube content into a searchable knowledge base. Here’s what you learned:- YouTube ingestion: Extract transcripts from playlists and individual videos with a single API call — no manual downloading or processing
- Metadata tagging: Label content by type (
conference,podcast) during ingestion for downstream filtering - Smart routing: Use an LLM to classify questions and automatically search the right source
- Q&A generation: Generate answers with citations from routed results
- Video recommendations: Return video suggestions instead of synthesized answers
Next steps
- Multimodal Input - YouTube ingestion options, transcript languages, and supported formats
- Filtering operators - Learn
$in,$or,$existsfor complex queries - Citations - Advanced citation patterns for your UI
- Agentic Search — Let the model search on its own for complex questions