Core technologies
Overview
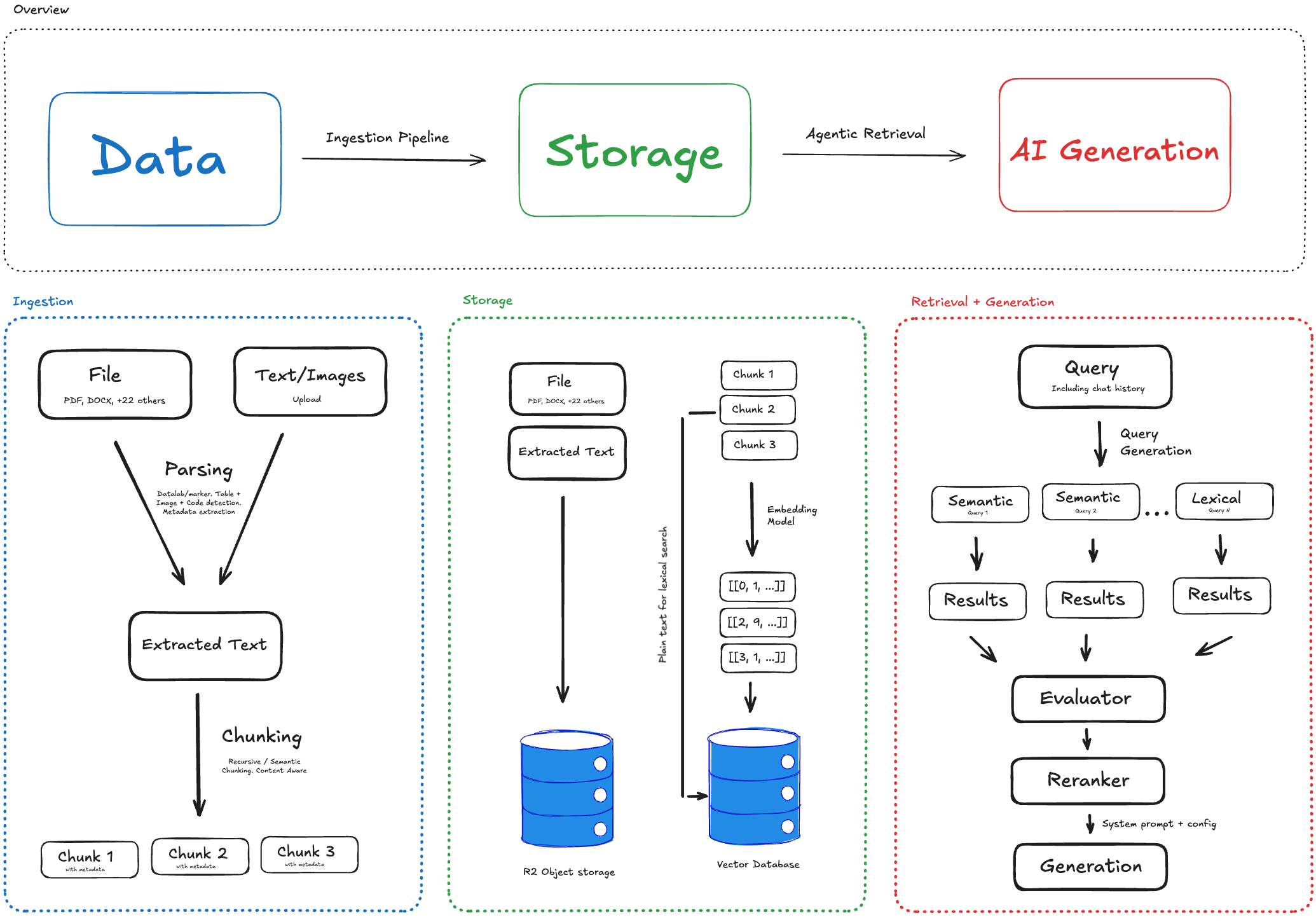
Ingestion
When you upload a file or text, it enters the ingestion pipeline:- Parsing — Documents are parsed to extract text, tables, and layout. Scanned content goes through OCR. Multimodal content is either extracted using an LLM descriptor or natively embedded.
- Chunking — Extracted text is split into chunks. Chunk boundaries respect sentence and paragraph structure. Specialized chunkers are used when processing tables, images, and code blocks.
Storage
Each chunk is embedded and stored in two places:- Object storage (R2) — The original file, extracted text, and metadata are persisted for retrieval and future reprocessing. This is also used for the chunk viewer UI.
- Vector database (Turbopuffer) — Embeddings are indexed for semantic search. Chunks’ plain text is used for lexical search. Turbopuffer caches hot namespaces on NVMe SSD, so subsequent queries to the same namespace are fast.
Retrieval
Standard RAG pipelines embed the query, find the nearest vectors, and return results once. This approach covers only a limited portion of the search space, can’t handle multi-hop questions, and is bound by chunk boundaries (i.e. if information is split across 2 or more chunks). For question answering, Agentset runs agentic retrieval instead of single-shot search. A retrieval agent—heavily inspired by agentic coding tools such as Claude Code and Cursor—searches the namespace in a tool-calling loop until it can answer:- Search — Run a semantic search (vector database + reranker) or a keyword search (lexical matching for exact terms) with a query the agent writes.
- Expand — Fetch the chunks before and after a result to read past chunk boundaries.
Next steps
- Quickstart — Build your first RAG pipeline
- Benchmarks — Compare retrieval accuracy
- Chunking settings — Configure how documents are split
- Search — Query your documents
- Self-hosting — Deploy on your own infrastructure